
4基于Intel Vt技术的Linux内核调试器 - 调试器设计与实现(2):调试核心
陈莉君 2012年09月20日 星期四 23:40 | 3692次浏览 | 0条评论
4.1 反汇编引擎
如果说调试框架是一个调试器的灵魂,那么接口与反汇编引擎就是一个调试器的身体。我们在调试过程中是要阅读指令代码的,而反汇编引擎则提供将二进制元指令翻译成可阅读的汇编代码这个功能。
设计并实现一个初级的反汇编引擎很简单,但是计算机指令系统并不简单,将这个反汇编引擎实现到可以实际应用的级别需要不断地调试与修复Bugs,这个过程需要耗费大量精力。所以我选择了开源反汇编引擎。虽然网上有很多开源反汇编引擎,但是大部分都依赖于用户态的C库,导致不能很好地移植到内核模块上使用,而且具有优秀效率的反汇编引擎很少。这里我选择了libudis86,它是一个开源反汇编引擎,我只对其语法转换部分进行了一些修改,使其反汇编出来的指令格式符合比较好的阅读习惯。
4.1.1 libudis86的基本使用方法
Libudis86库的使用很简单,只要一个提供各种信息的结构体,调用ud_disasmembe函数即可。例如下面定义了一个反汇编某个指令的函数:
ULONG OriDisasm(PUCHAR str,ULONG Eip)
{
UDIS ud_obj;
ULONG len;
ud_init(&ud_obj); //初始化结构体
ud_set_mode(&ud_obj, 32); //设置为32位元CPU模式
ud_set_syntax(&ud_obj, UD_SYN_INTEL); //结果使用Intel语法
ud_set_pc(&ud_obj,(int)Eip); //设置反汇编起点
ud_set_input_buffer(&ud_obj, (uint8_t*)Eip, 32); //设置输入缓冲区
len = ud_disassemble(&ud_obj); //开始反汇编
strcpy(str,ud_insn_asm(&ud_obj)); //复制结果
return len;
}
该函数反汇编Eip指向的二进制元指令码,将结果复制到str指向的缓冲区中。
4.1.2 使用libudis86反汇编某段程序
上面的函数OriDisasm只能反汇编一条指令,通常我们的调试器需要反汇编一段程序。 OriDisasm在反汇编一条指令结束后会返回该指令长度(位元组),递增指令指针循环继续这项操作即可反汇编一段代码。
4.1.3 向上反汇编:递减命中率算法
调试器的反汇编窗口应该像控制台窗口一样具有翻页功能,这样便于我们查阅反汇编代码,但是单纯地使用libudis86只能从上往下进行反汇编,如果我们需要向上翻页,则需要从下往上翻页。看似简单,实际上有一个很重要的难题。
我们知道x86汇编指令是不定长的,一条指令可能最小只占用1个字节,最长可能占用15个字节,而我们并不知道某一条指令它的上一条指令占用多少个位元组,因此不能直接获取某一条指令的上一条指令是什么。例如下面的指令:
004017F0 75 64 jnz short 00401856
004017F2 8B45 10 mov eax, dword ptr [ebp+10]
004017F5 C1E8 10 shr eax, 10
004017F8 83F8 07 cmp eax, 7
第一列是指令位址,第二列是指令二进制元编码,第三列是对应的汇编代码。假设当前我们反汇编的位置是4017F8那么我们对这个内存位置的83 F8 07进行反汇编可以得到cmp eax,7这条指令,但是我们并不知道这条指令的上一条指令从什么位址开始,如果我们贸然猜测上一条指令的位址显然我们会得到一个错误的反汇编结果。例如对4017F6反汇编得到:
004017F6 E8 1083F807 call 08389B0B
结果是一个占用5个位元组的call指令,而且这个指令覆盖了位于4017F8本来正确的结果。
我设计了一个算法用以解决这个问题,算法的思想是递减地址指针,从这个指标开始向下循环反汇编,当长度刚刚好到达我们预期的位置时,记录上一条指令的位置。然后将这些结果进行统计。
例如当前指令是
004017F8 83F8 07 cmp eax, 7
我们想要知道他的上一条指令是什么,就递减地址,得到4017F7,反汇编得到:
004017F7 1083 F807754B adc byte ptr [ebx+4B7507F8], al
结果覆盖了4017F8,此结果作废。继续向上递减。
004017F6 E8 1083F807 call 08389B0B
结果覆盖了4017F8,此结果作废。继续向上递减。
004017F5 C1E8 10 shr eax, 10
004017F8 83F8 07 cmp eax, 7
结果可能正确,记录下上一条指令位址4017F5,命中率为1次。
继续向上递减。
004017F4 10C1 adc cl, al
004017F6 E8 1083F807 call 08389B0B
覆盖了4017F8,此结果作废。继续向上递减。
004017F3 45 inc ebp
004017F4 10C1 adc cl, al
004017F6 E8 1083F807 call 08389B0B
覆盖了4017F8,此结果作废。继续向上递减。
004017F2 8B45 10 mov eax, dword ptr [ebp+10]
004017F5 C1E8 10 shr eax, 10
004017F8 83F8 07 cmp eax, 7
刚好得到4017F8,记录下4017F8的上一条指令是4017F5,因为刚刚记录命中了一次,因此当前的统计结果是:4017F8上一条指令4017F5,命中率2次。
就这样继续不断递减地址,从递减后的地址向下反汇编,当结果刚好可以到达4017F8时记录下上一条指令位址。假设我们向上递减200字节,记录结果可能如下。
4017F5 40次
XXXXXX 1次
那么根据统计结果上看,上一条指令有很大可能是从4017F5开始,那么我就可以认为上一条指令是4017F5。当然这个结论可能不正确,因为这毕竟是统计学结果。如果想要得到更准确的结果,我们可以采样更多的数据,例如向上递减1000字节。以保证结果的可靠性。
实现好的代码片段如下:
typedef struct {
ULONG pInstrAddr; //上一条指令的位址
ULONG HitCount; //命中次数
}PREV_INSTR_HITTEST,*PPREV_INSTR_HITTEST;
ULONG GetPrevIp(ULONG Eip)
{
PREV_INSTR_HITTEST HitTest[16];
ULONG CurrentAddr = Eip - 1;
ULONG PrevAddr;
ULONG DisasmLimit = 0x100;
ULONG len;
ULONG i;
ULONG PrevAddr_MaxHit = 0;
ULONG MaxHit = 0;
if(!Eip)
return FALSE;
memset(&HitTest,0,sizeof(HitTest));
while(DisasmLimit)
{
PrevAddr = CurrentAddr;
if(!IsAddressExist(PrevAddr)) //保证地址空间可读
break;
while(1)
{
len = FastDisasm(PrevAddr);
if(len != -1 && len)
{
if(len + PrevAddr >= Eip)
{
AddHit(&HitTest[0],16,PrevAddr);
break;
}
else if(len + PrevAddr > Eip)
{
break;
}
}
else
{
break;
}
PrevAddr += len;
}
DisasmLimit--;
CurrentAddr--;
}
for(i = 0; i < 16; i++)
{
if(HitTest[i].HitCount > MaxHit)
{
MaxHit = HitTest[i].HitCount;
PrevAddr_MaxHit = HitTest[i].pInstrAddr;
}
}
return PrevAddr_MaxHit;
}
4.2 调试控制台
调试控制台是整个调试器的工作中心,这个控制台将响应用户的一切输入,完成用户所需的调试功能。
4.2.1 命令解析
4.2.1.1 数据结构的设计
我将所有命令统一定义在一张表里,这个表是如下的数据结构:
typedef struct{
CHAR *Cmd; //命令前缀
CHAR *Desc; //命令描述
CHAR *Usage; //命令用法描述
CHAR *Example; //命令用例
PCMD_HANDLER pHandler; //命令分发处理函数
}CMD_HELP, *PCMD_HELP;
这样我就可以把所有命令统一定义,如下所示:
CMD_HELP CmdHelp[] = {
{"BC","Clear breakpoint","BC [*|id]",NULL,CmdClearBreakpoint},
{"BL","List current breakpoints","No param for BL",NULL,CmdListBreakpoint},
{"BPX","Breakpoint on execute","BPX [addr] if [condition] do [cmd]","bpx ntsetvaluekey if \"[[esp+8]+4]==\"imagepath\"\" do \"? byte [esp+4]\"\n",CmdSetSwBreakpoint},
{"CPU","Display cpu registers information","No param for CPU",NULL,CmdDisplayCpuReg},
{"!DB","Display physical memory(byte)","!DB [address]","!db 39000\n",CmdDisplayPhysicalMemoryByte},
{"!DW","Display physical memory(word)","!DW [address]","!dw 39000\n",CmdDisplayPhysicalMemoryWord},
{"!DD","Display physical memory(dword)","!DD [address]","!dd 39000\n",CmdDisplayPhysicalMemoryDword},
{"DB","Display memory(byte)","DB [address|symbolname]","db [esp+4]\n",CmdDisplayMemoryByte},
{"DW","Display memory(word)","DW [address|symbolname]","dw [esp+4]\n",CmdDisplayMemoryWord},
{"DD","Display memory(dword)","DD [address|symbolname]","dd [esp+4]\n",CmdDisplayMemoryDword},
};
这样定义有以下几个好处:
1、实现命令提示功能,例如输入一个B的时候,通过查这张表可以将所有B打头的指令列出来,让用户一目了然B打头的指令有哪些。
2、当用户输入了一个确定的指令例如BPX时,可以将BPX的语法自动提示给用户。
3、当用户输入H BPX请求BPX指令的用法时。可以将BPX指令的语法和用例打印出来。
4、结构体定义了命令分发处理函数,例如输入BPX就可以跳转到BPX处理函数CmdSetSwBreakpoint,由BPX函数负责解析这个函数。输入BC则跳转到BC处理函数CmdClearBreakpoint中。
4.2.1.2 帮助信息与命令提示
有了上述定义的表,就可以很方便地获取指令帮助信息和命令提示功能。只需枚举表项即可。
4.2.1.3 一般命令的解析
首先对输入语句的开头进行判断,进入相应的命令处理函数中,继续分割出命令的所有参数,然后对参数进行数值转换处理,例如可能需要将字符串转换成10进制或16进制数值类型。最后实现该命令。
4.2.1.4 使用LL-1分析法计算表达式
有些时候我们需要输入表达式,例如查看esi+14h处指针指向的内存数据,使用命令:
dd [esi+eax*4+14]
[esi+eax*4+14]就是一个表达式,首先计算esi+eax*4+14,方括号表示对指标取值,得到该指针处的地址。
对表达式的分析我使用了LL-1分析法:算法从左到右分析表达式,设置符号栈和值栈,例如对表达式[1+4]>=45&&(([1+8]<9)||([1+c]&10))分析,步骤如下:
表4-1:LL-1分析法计算步骤
|
符号栈 |
值栈 |
串 |
|
[ |
|
1 |
|
[ |
1 |
+4]>=45&&(([1+8]<9)||([1+c]&10)) |
|
[ + |
1 |
4]>=45&&(([1+8]<9)||([1+c]&10)) |
|
[ + |
1 4 |
]>=45&&(([1+8]<9)||([1+c]&10)) |
|
|
[5] |
>=45&&(([1+8]<9)||([1+c]&10)) |
|
>= |
[5] |
45&&(([1+8]<9)||([1+c]&10)) |
|
>= |
[5] 45 |
&&(([1+8]<9)||([1+c]&10)) |
|
&& |
1 |
(([1+8]<9)||([1+c]&10)) |
|
&& ( |
1 |
([1+8]<9)||([1+c]&10)) |
|
&& ( ( |
1 |
[1+8]<9)||([1+c]&10)) |
|
&& ( ( [ |
1 |
1+8]<9)||([1+c]&10)) |
|
&& ( ( [ |
1 1 |
+8]<9)||([1+c]&10)) |
|
&& ( ( [ + |
1 1 |
8]<9)||([1+c]&10)) |
|
&& ( ( [ + |
1 1 8 |
]<9)||([1+c]&10)) |
|
&& ( ( |
1 [9] |
<9)||([1+c]&10)) |
|
&& ( ( < |
1 [9] |
9)||([1+c]&10)) |
|
&& ( ( < |
1 [9] 9 |
)||([1+c]&10)) |
|
&& ( |
1 0 |
||([1+c]&10)) |
|
&& ( || |
1 0 |
([1+c]&10)) |
|
&& ( || ( |
1 0 |
[1+c]&10)) |
|
&& ( || ( [ |
1 0 |
1+c]&10)) |
|
&& ( || ( [ |
1 0 1 |
+c]&10)) |
|
&& ( || ( [ + |
1 0 1 |
c]&10)) |
|
&& ( || ( [ + |
1 0 1 c |
]&10)) |
|
&& ( || ( |
1 0 1c |
&10)) |
|
&& ( || ( & |
1 0 1c |
10)) |
|
&& ( || ( & |
1 0 1c 10 |
)) |
|
&& ( || |
1 0 1 |
) |
|
&& |
1 1 |
|
|
|
1 |
|
详细算法实现见exp.c和exp.h文件。
4.2.2 单步步入
单步步入是单步执行的一种,他会让调试器跟踪进入到call指向的函数中。
4.2.2.1 设置单步
首先设置一个全局变量表示当前正在进行单步,然后设置单步陷阱标志EFLAGS.TF,并备份当前屏幕。已备退出单步返回操作系统时恢复屏幕。
需要注意的是,单步时需要清空客户机GUEST_INTERRUPTIBILITY_INFO域、GUEST_ACTIVITY_STATE域,否则在单步CLI指令后会死机。这个bug在hyperdbg中存在,我曾与hyperdbg作者讨论这个问题,最终在Intel手册中找到相关解释。
4.2.2.2 回应单步
设置单步陷阱标志后,执行当前指令后会引发DEBUG异常,即单步异常。异常引发后进入我们的VM Exit处理函数中。我们判断当前为单步操作,进行相应的动作,例如显示反汇编代码,高亮当前汇编代码等等操作。
4.2.2.3 取消单步
取消单步只需要撤销单步陷阱标志TF即可。
4.2.3 设置断点
设置断点的原理是替换某个指令为INT 3指令,当程序执行到这个INT 3指令后就会断下来,调试器获得执行机会,继续这条指令的执行前需要恢复原指令,因为原指令已经被替换成了INT 3。
4.2.3.1 数据结构的设计
我定义了如下的结构用于描述一个断点:
typedef struct{
ULONG ProcessCR3; //进程页目录
USHORT CodeSeg; //代码段
ULONG Address; //断点地址
CHAR OldOpcode; //断点位址处原指令备份
CHAR IfCondition[128]; //条件表达式
CHAR DoCmd[128]; //满足条件后运行的语句
}SW_BP, *PSW_BP;
一般调试器允许设置的断点数量有限,数组即可满足我们的需求,定义一个全局数组用于保存当前所有的断点。
4.2.3.2 设置断点
首先检查断点数组是否满,找到一个空项,填写相关信息诸如进程页目录,地址,备份原指令。最后将断点处第一个字节写入CC字节(INT 3指令)即可。
#define INT3_OPCODE 0xCC
4.2.3.3 回应断点
当CPU执行INT 3指令后引发BREAKPOINT异常,即断点异常,然后进入我们的VM Exit处理函数,枚举断点数组,判断是否为我们的断点,如果不是则将异常投递回客户机交给客户机操作系统处理,如果是我们的断点,则做出相应动作诸如显示反汇编代码,高亮汇编代码等。
当我们选择执行这个指令时,调试器将该断点处位址的原指令恢复,然后交给CPU继续运行这段代码。
但是一旦断点被恢复为原指令后这个断点便不再生效,有时我们希望一个断点可以被多次触发。因此还需要做一些额外操作。我使用的方法是设置一个单步陷阱,当执行过被断点的指令后,调试器会再次获得执行机会,这时我们把上一条指令恢复成INT 3指令,这个断点就可以继续发挥作用了。
4.2.3.4 清除断点
清除某一个断点,首先应当得到这个断点的位置,恢复该位置的指令,最后把对应的断点描述结构清空即可。
4.2.4 单步步过
单步步过是单步执行的另一种,他不会让调试器跟踪进入到call指向的函数中。而是跳过call执行。
4.2.4.1 设置单步步过断点
在单步非call指令时都是通过设置单步陷阱标志Eflags.TF来实现的,但是在设置标志前多一项工作:检查当前指令是否为call。如果当前指令为call,则不设置TF标志,而是将call指令的吓一跳指令设置为断点指令INT 3,这样当call执行完毕后就会触发断点异常,从而实现单步步过call的功能。
设置断点需要一个结构体来描述一个断点信息以及备份指令,这个结构体其实就是SW_BP,只是换了一个名字,用另外一个数组来描述他。
4.2.4.2 回应断点及清除断点
触发断点异常后首先检查是否为用户设置的断点,如果不是则检查是否为单步步过的断点。当属于单步步过的断点时,就自动恢复断点处的原指令,并删除该断点,因为这种断点我们只使用了一次,触发后就不再需要他了。
4.3 其它功能
单步和断点功能是一个调试器最基本的功能,另外还应该有一些常用功能来辅助调试工作。
4.3.1 查看内存数据
我一共实现了3个查看内存数据的指令分别是按位元组查看,按字查看,按双字查看。命令分别为DB、DW、DD。就是将某处内存读出并按照相应的格式输出即可。
4.3.2 查看页面信息
页面信息功能可以查看某一个线性地址指向的物理内存地址,以及该页面的相关信息。通过查询PDE、PTE可以得到这些信息。
4.3.3 CallStack(堆栈回溯)
堆栈回溯也是调试器的重要功能,当程序发生崩溃被调试器拦截时,我们希望得知是由哪个函数调用导致的崩溃,堆栈回溯这个功能就派上了用场。
大部分x86编译器编译一个函数后,都生成了固定的函数帧头部,大致如下:
push ebp
mov esp,ebp
…
而且我们知道call指令的实现其实就是将返回地址压入堆栈并jmp到函数体。所以这样的函数帧头部会产生函数调用链。例如当A调用B,B调用C,在C中观察栈帧结构就如图4-1所示:
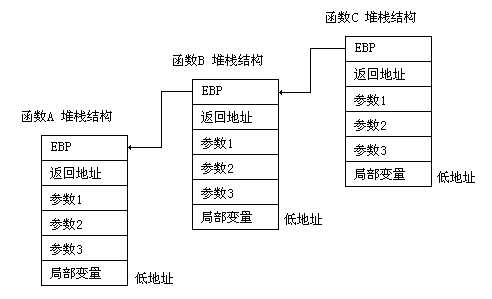
图4-1 堆栈结构图:A调用B,B调用C
因此,实现堆栈回溯只需要下面的代码即可完成:
while(EBP)
{
返回地址 = *(EBP+4);
打印信息;
EBP = *EBP;
}
4.3.4 查看CPU信息
这个功能可以实现查看CPU通用寄存器、控制寄存器等常用寄存器的值,以及解析出控制寄存器相应控制位,并在屏幕上打印输出它们。
4.3.5 查看中断描述表
这个功能可以读取当前CPU的中断描述表,并将对应的中断处理函数打印出来。
4.4 卸载调试器
卸载调试器其实就是虚拟化框架的卸载,也就是将运行在虚拟CPU上的操作系统“解救”出来,将他放回物理CPU上运行。
当位于虚拟CPU的操作系统执行我们调试器内核模块的module_exit函数时,会执行一个VMCALL指令,该指令引发VM Exit,进入到VM Exit处理函数,此时CPU模式为VMX root。
此时我们要做的工作很简单。判断是否是请求卸载调试器,如果是,则删除调试器的所有断点,恢复虚拟CPU的各种控制寄存器,执行VMXOFF指令关闭虚拟CPU,然后跳回module_exit函数即可。
这样之后操作系统就又重新回到物理CPU上面执行了,同样的道理,这就是CPU控制权的转移。
评论
Zeuux © 2026
京ICP备05028076号
暂时没有评论